Pxer设计思路(JavaScript爬虫)
可能有人一看到花生打算用JavaScript写爬虫感到不可思议,js竟然能写爬虫?!
其实用JavaScript写爬虫其实是有很多优势的(注意不是node.js)
- js直接可以直接在浏览器运行,所以每个人都可以拿来使用,即使是电脑小白
- 就如XSS攻击一样,当每个人拿到花生的写的爬虫程序使用时,就相当于大家都在帮忙爬取数据,这样可以避免被封杀
- js是事件驱动的,Ajax可以帮我们大忙
- js与HTML CSS关系紧密,可以很简单实现一个界面美观功能强大的程序
所以,一个“基于js的爬虫项目 —— Pxer ”诞生了。
实现原理
首先是如何运行Pxer,有2种方法
- 在Firefox中有一个插件叫做“Greasemonkey”,其作用是可以设点规则,在特定的网站中在网页中嵌入Js文件。直接设置在“pixiv.net”添加Pxer启动文件即可
- 利用浏览器书签可以执行js代码的特性,直接将Pxer启动文件代码复制进书签即可
在正式发布之前,为了调试方便,采用第二种方法来运行Pxer。
Pxer启动文件大概长这样:
[code lang="js"]
javascript:
void(( function() {
var script=document.createElement("script");
var date=new Date;
script.src="http://127.0.0.1/pxer/pxer4.0/js/run_pxer.js?"+date.getTime();
document.head.appendChild(script);
})());
[/code]
因为代码的开头有“javascript:”,所以复制进书签会当做js代码来解析。代码大体作用是在页面中插入一个本地的js文件,地址127.0.0.1是因为花生为了测试搭建了个wamp环境。
然后真正的pxer运行文件就开始运行了,运行文件大概长这样
[code lang="js"]
/*根路径*/
pxer_root='http://127.0.0.1/git_studio/pxer_encrypt/pxer';
pxer_nutjs='http://127.0.0.1/git_studio/warehouse/js'
/*要载入文件的列表
注意,列表文件会依次载入,载入完其中一个onload触发载入下一个
因此请将不能设置onload事件的标签放在末尾
*/
var load_arr=[
pxer_nutjs+'/nut2.0.js',
pxer_nutjs+'/nutjs_ex_ajax.js',
'/style/basic.css',
'/js/pxer.js',
'/js/initialize.js',
'/image/favicon.ico'
];
/*系统变量*/
var load_parser={
'php?' : {
"tag" : "script",
"url" : "src",
"add" :{"type":"text/javascript"}
},
'js' : {
"tag" : "script",
"url" : "src",
"add" :{"type":"text/javascript"}
},
'ico' : {
"tag" : "link",
"url" : "href",
"add" :{"rel":"shortcut icon"}
},
'css' : {
"tag" : "link",
"url" : "href",
"add" :{"rel":"stylesheet"}
}
};
/*载入配置文件*/
var all_loadElt=[];/*要加载的节点*/
var temp_url='';
var temp_elt=null;
var date=new Date;
var tagName;
for(var i=0; i<load_arr.length ;i++){
/*将相对路径转换为硬路径*/
if(/^http/.test(load_arr[i])){
temp_url=load_arr[i];
}else{
temp_url=pxer_root+load_arr[i];
};
/*初始化all_arrH*/
if(/\.((\w+)$|(\w+)\?)/.test(temp_url) && load_parser[tagName=RegExp.$1]){
temp_elt= document.createElement(load_parser[tagName].tag);
if(/\?/.test(tagName)){
temp_elt[(load_parser[tagName].url)] =temp_url+"&date="+date.getTime();
}else{
temp_elt[(load_parser[tagName].url)] =temp_url+"?"+date.getTime();
};
if(load_parser[tagName].add){
for(var key in load_parser[tagName].add){
temp_elt.setAttribute( key, (load_parser[tagName].add)[key] );
};
};
all_loadElt.push(temp_elt);
}else{
alert('Error:\nunknow URL type in "'+tagName+'"');
throw new Error();
};
};
/*载入节点*/
for(var i=0;i<all_loadElt.length -1;i++){
all_loadElt[i].onload=function(){
for(var i=0;i<all_loadElt.length -1;i++){
if(this == all_loadElt[i]){
document.head.appendChild(all_loadElt[i+1]);
}
}
};
};
document.head.appendChild(all_loadElt[0]);
[/code]
这个是真正的Pxer运行代码,在页面中插入很多个Pxer必备的文件,其中包括了一个叫做nutjs的小js类库。
关于Pixiv
然后介绍下pixiv.net网站(以下简称P站):
P站是提供一个能让艺术家发表他们的插图,并通过评级系统反应其他用户意见之处,网站以用户投稿的原创图画为中心。
简单的说,P站为一些二次元画师提供一个投稿平台,每一个画师都可以在P站中注册一名会员,然后上传自己的作品。当然,也可以像花生这样只看那些画师投稿,纯粹的欣赏。
但是,P站不提供作品批量下载功能!!!也就是说,如果花生喜欢一名画师,他有500副作品,花生如果想要保存至电脑,只能一副一副的右键另存为!!然后花生就受不了了,一怒之下写一个爬虫来实现批量下载这个功能,所以Pxer主要具有以下功能:
- Pxer是用来爬取P站的专用爬虫
- Pxer可以爬取到P站中的图片信息,比如下载地址、评分值、画师ID
- Pxer可以实现P站图片批量下载(输出所有图片下载地址,再借助第三方下载软件即可)
- Pxer可以根据用户的喜好来过滤数据,比如用户可以选择仅爬取评分大于1000点的作品
- Pxer可以实现一些常用的快捷操作,使网站更符合国人上网习惯
实现过程
然后花生就开工了,一开始的Pxer是采用DOM操作来爬取数据,直接getElement,后来发现Ajax比较快,然后就采用Ajax爬取数据了,花生的电脑,挂上代理,速度大概是 4张/秒,感觉网速不给力,其实应该非常快才对,不过考虑到P站的服务器在日本,这个速度勉强可以接受,起码比右键另存为快多了!
当用户点击Pxer启动书签或者通过小油猴自动启动Pxer,在P站的网页中就好嵌入一个小模块,如下图。在网页中有一个Pxerβ 4.0就是Pxer的界面,按照花生喜欢的风格设计的,与P站本身融于一体,即使日常不用Pxer的爬取功能也不会耽误正常的访问,还提供一系列的便捷操作,比如针对性的去广告,优化页面,让页面更符合国人操作习惯等等等。
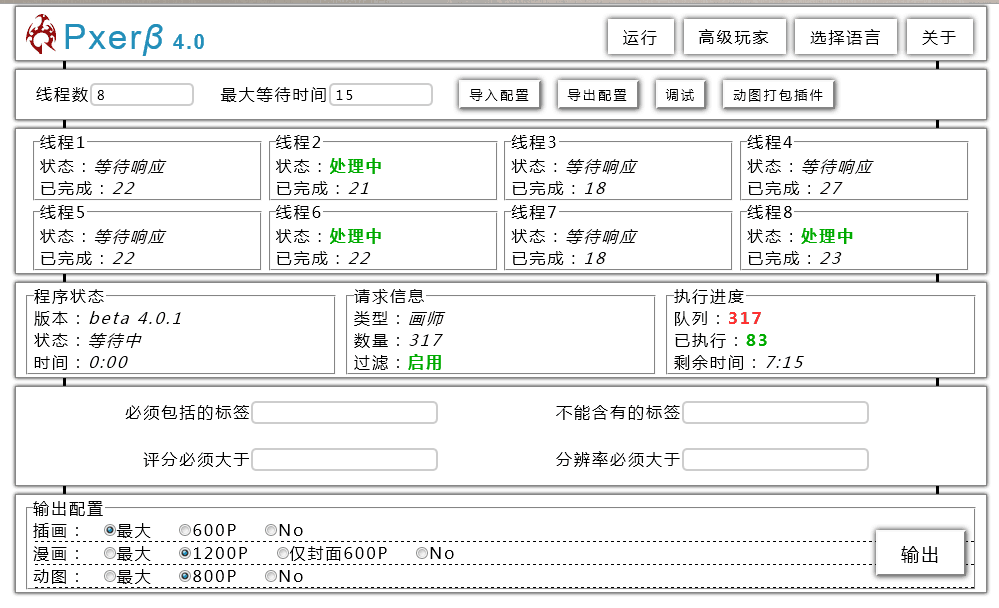
为了用户体验Pxer设计的很mini,不过如果如果完整展开,Pxer是有很多个模块的,完整展开大概长这样
写起这个爬虫,感觉其中的难度比花生想象的难度要大很多,因为要考虑到所有的情况,用户有可能在任何页面使用Pxer点击任何功能,花生不得不拿出很大一部分的精力去考虑用户有可能会产生什么愚蠢的操作,Pxer应该如何指引用户......
随便放出其中的一个控制函数大家感受下
[code lang="js"]
PxGet.prototype. get=function(){
if(this.isOK()) return this.fn();
if(this.pr.type){
switch(this.pr.type){
case 'pic':
if(this.address){
this.get_pr_from_address();
}else if(this.workHtml){
this.get_address_from_workHtml();
}else if(this.workUrl){
this.get_workHtml_from_workUrl();
return;
}else{
this.pr.type=null;
};
break;
case 'ids':
if(this.address){
this.get_pr_from_address();
}else if(this.idsUrl1Html || this.idsUrl2Html){
if(this.idsUrl1Html && this.idsUrl2Html){
this.get_address_from_idsUrl2Html();
this.get_prPicnum_from_idsUrl1Html();
}else{
return;
};
}else if(this.idsUrl1 && this.idsUrl2){
this.get_idsUrl1Html_from_idsUrl1();
this.get_idsUrl2Html_from_idsUrl2();
return;
}else if(this.workId){
this.get_idsUrlx_from_workId();
}else if(this.workHtml){
this.get_workId_from_workHtml();
}else if(this.workUrl){
this.get_workHtml_from_workUrl();
return;
}else{
this.pr.type=null;
};
break;
case 'sids':
if(this.workHtml){
this.get_pr_from_workHtml();
}else if(this.workUrl){
this.get_workHtml_from_workUrl();
return;
}else{
this.pr.type=null;
};
break;
case 'zip':
if(this.address){
this.get_pr_from_address();
}else if(this.workHtml){
this.get_address_zipo_from_workHtml_zip();
}else if(this.workUrl){
this.get_workHtml_from_workUrl();
return;
}else{
this.pr.type=null;
};
break;
default:
nutjs.le('函数PxGet.get,未知的prType值【'+this.pr.type+"】");
};
}else{
if(this.workHtml){
this.get_prType_from_workHtml();
}else if(this.workUrl){
this.get_workHtml_from_workUrl();
return;
}else if(this.workId){
this.get_workUrl_from_workId();
}else{
nutjs.le("函数PxGet.get,参数不足以获取");
};
};
this.get();
};
[/code]
还好花生这次机智的采用了面向对象的写法,比之前的面向过程清晰不少,而且代码量也少了很多。
之前采用批量打开页面Dom获取简直是......
不过依旧比较乱
- 标签:JavaScript,Pxer
- 浏览:14043
- 评论:7
夜煞 2016年5月10日 下午8:04
花生好久不见~话说前段时间用Python写过教务网爬虫来着,完成了验证码识别模块,结果request给服务器死活不响应,最后项目还是流产了
花生PeA 2016年5月10日 下午9:10
是不是服务器校验了Referer请求头?一般来说只有请求头(包括Cookie)和IP校验
夜煞 2016年5月11日 上午10:51
不是,headers当然伪造了= =。说错了不是服务器不响应,刚上手用urllib12库不支持chunk传输,服务器返回connection:close,然后改用requests库,服务器已经返回了keep-alive,感觉问题出在session,可能验证码和cookie一一对应的?最近学的太杂了,有空再折腾=。=
monburan 2016年3月31日 下午7:51
请问图片最大输出是怎么实现的?
花生PeA 2016年4月8日 上午9:03
你是说下载地址的计算吗?仔细观察发现小图地址和大图地址长大差不多,用正则替换替换就好了
扎易 2015年10月19日 上午9:32
JavaScript爬虫能否在Linux平台上长期运行?
一般Python爬虫都是先写出原型,然后要么挂在Linux上,要么用诸如PyQt之类的平台写个桌面窗口供Windows用户试用
花生PeA 2015年10月25日 下午1:15
可以的,服务器可以搭建一个node.js来执行解析JavaScript。
不过js还是在客户端部分比较有优势